Fact Benchmark API
Intro
The API aims to provide access to a shared data resource whereby researchers working in the field can collaborate to push the state of the art in realtime fact checking.
As a design goal, where-ever possible the data available via the API is designed to be immutable, non-revokable, timestamped, independently verifiable (signed) and trustless. This design constraint supports our future design goals as well as our data transparency objectives.
There are three aspects to the API.
A simple REST API for read and create operations
A REST endpoint allows agents to create (POST) resources and retrieve (GET) resources by id or hash. The following resources are available (as explained in more detail below):
- claims
- responses
- annotations
- benchmarks
- content
- revokes
- agents
With the exception of the agents end point, update operations are not supported with this API because all operations are designed to be CRDT. However the revoke end point provides a mechanism where by agents (including factbenchmark.org itself) can post ‘hide’ flags. Operations on the REST API do not honour ‘hide’ flags but other API operations may.
The REST API does not provide documented complex query semantics because the GraphQL API provides better support for query based use cases.
GraphQL Query API for complex queries and notification
A GraphQL end point provides clean semantics for read query operations such as search and aggregation.
A self-documenting example of the GraphQL API is available here
The GraphQL end point also provides notifications via subscriptions including:
- claims {all, by_agent, checkworthy>x, truthiness>x, truthiness<x, accepted_by_benchmark}
- responses {all, by_agent, by_claim, related_to_benchmark}
- annotations{all, by_agent, for_claim}
Bulk Feed API
Finally, there is a read only end point that provides access to data in flattened format for bulk download and analysis purposes. We wish to be guided by our members as to the necessity and preferred format for this end point.
Inviting feedback
The overall goal of this roject to support and provide a resource to our stakeholders and member organisations. For that reason, we are obviously very keen to receive your feedback or thoughts on any aspect of this project. This is is especially important in the case of the design of the API.
We are using the excellent hypothes.is tool to make this easy. If you have thoughts about anything on this page, simply select the text on this page and use the tooltip that pops up to add your comments. Registration with hypothesis is free and easy.
Alternatively, if you prefer, feedback is also welcomed by email to: info@factbenchmark.org
REST API
Claim
A claim is a short statement which should be falsifiable and of general interest.
To be regarded as check worthy a claim should be ‘falsifiable’, in that it:
- is phrased in a non-ambiguous way
- is not a prediction about the future
- relates to (potentially) verifiable information
- is not phrased as a question or inquiry
- is not a normative statement (“our policy is small business focused”)
To be regarded as check worthy a claim should also be ‘of general interest’ due to one or more of the following reasons:
- it relates to a generally active public discussion or rumor .. or ..
- it is attributed to an important person of interest .. or ..
- it is otherwise important enough to be of importance to a number of people
The claim_text is the definitive text that should be evaluated for truth or falsity. It doesn’t necessarily exactly match the text from the source (if any), but should be close to it.
The timestamp is the time of attribution to the original claim (if any)
Example (with expansion of the attributions annotation, per below)
{
"self": { "href": "claim/5355b6c6-b620-411b-9eb5-7e73f7146cbf"},
"claim_text": "Student arrested for shouting slogans against BJP in Tamil Nadu",
"claim_timestamp": "2018-09-04T04:29:00.000Z",
"attributions": [
{ "source-url": "https://twitter.com/anindita-guha/status/1036924232595382273",
"snapshot": { "hash": "3d8c26e642e3b" },
"submitted_by": { "href": "agent/faktist16"},
"created": "2019-01-01T01:23:00.000Z"
}
],
"submitted_by": { "href": "agent/faktist16"},
"created": "2019-01-01T01:23:00.000Z"
}
Claim-Response
In this version of the benchmark check_worthy claims are submitted by members and then, also, evaluated by members.
The first step is to decide whether a claim is check_worthy, then to evaluate its truth or falsehood.
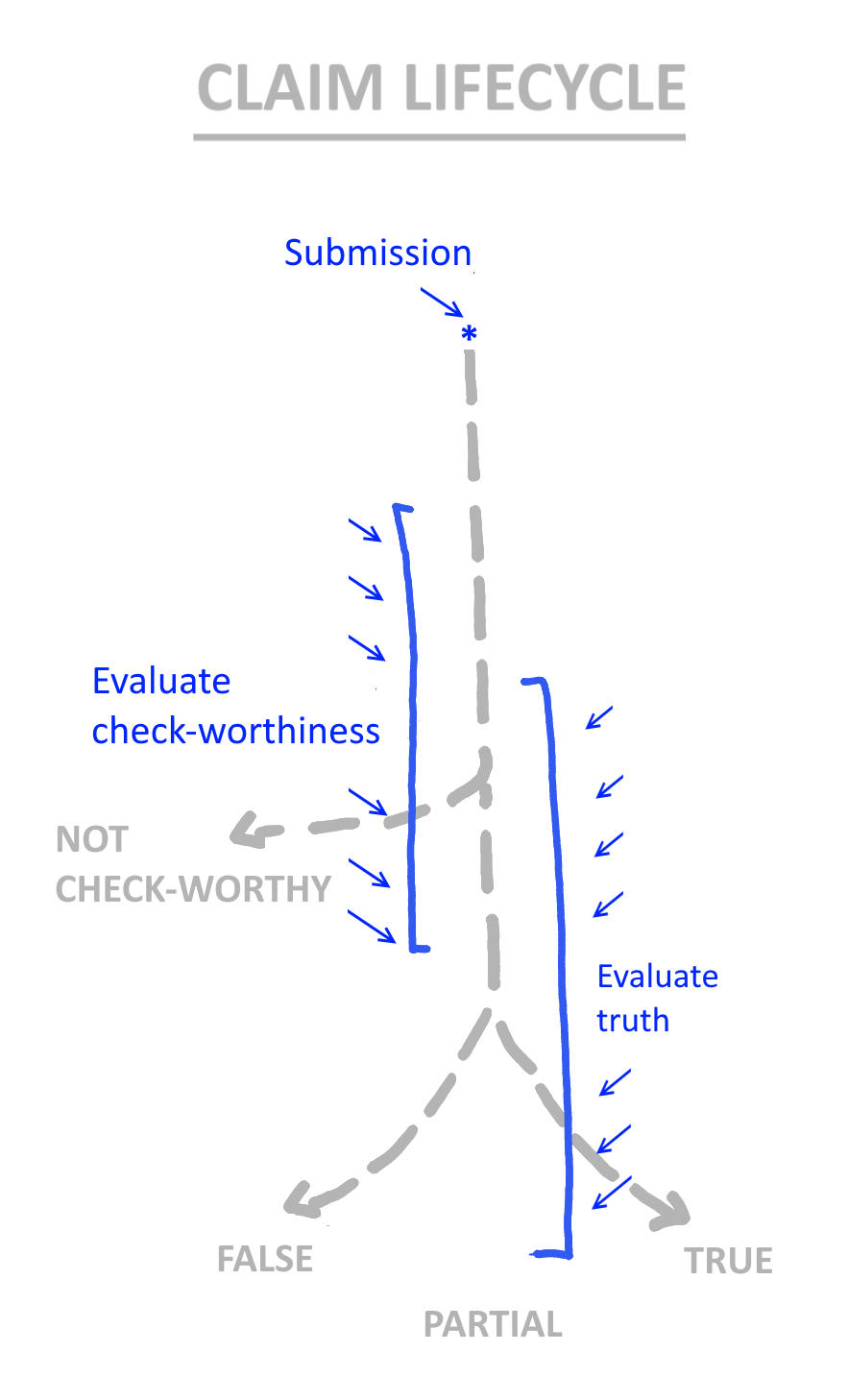
It is expected that a claim will usually to be evaluated for check-worthiness prior to being evaluated for truthiness, but this is not required. Agents can respond with any or all three parts of the claim-response at any time.
There are three parts of a claim response, any of which can be provided at any time.
check_worthyis a section indicating whether or not the claim is check_worthy.truth_ratingis a section indicating whether the claim is true, false, or partially true.annotationis a section for arbitrary data.
A given user can respond multiple times to the same claim (and often will).
Submitting a claim (or providing a truth_rating without a check_worthy section) is taken to be implcit acknowledgement that the claim is check_worthy (equivalent to "check_worthy": {"importance":1}).
check_worthy
The simplest way to respond to a claim is to simply post "check_worthy": true which is equivalent to giving it a ‘check-worthiness’ of 1.
For example:
{
"ref": { "href": "claim/7dc0051f" },
"check_worthy": true,
"submitted_by": { "href": "agent/joef2016"},
"created": "2019-01-01T01:23:00.000Z"
}
Alternatively a response may simply indicate that the agent chooses not to rate this claim. In such cases the check_worthiness is implicitly assumed to be 0.
{
"ref": { "href": "claim/7dc0051f" },
"check_worthy": {
"decline-to-rate": {
"reason": "not falsifiable - statement of opinion"
}
},
"submitted_by": { "href": "agent/joef2016"},
"created": "2019-01-01T01:23:00.000Z"
}
It is not required, but it is helpful to provide a reason when posting a decline-to-rate. For now this is free text content, but we may add an additional taxonomy field once we see what reasons are most common (if any).
It is also possible to provide a partial check_worthiness claim, such as in the case where the claim is check worthy but there is a better formulation of the claim.
A better-option with a related claim can be supplied explicitly within a decline-to-rate section. For example:
{
"ref": { "href": "claim/7dc0051f" },
"check_worthy": {
"check_worthiness": 0.3,
"decline_to_rate": {
"reason": "not falsifiable - better options exist",
"related": { "href": "claim/5d81f18d" }
}
},
"submitted_by": { "href": "agent/joef2016" },
"created": "2019-01-01T01:23:00.000Z"
}
Benchmarks will generally endeavor to include claims with the highest, expected value of ‘check-worthiness’. In the case where the are many related claims, benchmarks will prefer to choose only one or two from the cluster having the highest rating for check worthiness.
During the alpha phase trial, check worthy claims will be hand curated.
truth_rating
If an agent views a claim as check_worthy they may choose to include a ‘truth_rating’ section in their response.
There are two primary ways that a truth_rating can be indicated:
- A boolean indicating whether the claim is, simply ‘true’ or ‘false’.
- A truthiness value between 0 and 1 indicating ‘how true’.
It is worth bearing in mind that these two options exist within the context of the wider range of responses, such as declining to rate, or simply annotating the claim with arbitrary content.
The truthiness should be interpreted as the degree to which the statement itself is true, not the confidence that the agent has in their rating. That is, a truthiness of 0.6 indicates ‘partially true’, not ‘probably true’.
For example:
{
"ref": { "href": "claim/7dc0051f" },
"truth_rating": {
"truthiness": false,
},
"submitted_by": { "href": "agent/joef2016"},
"created": "2019-01-01T01:23:00.000Z"
}
Or:
{
"ref": { "href": "claim/7dc0051f" },
"truth_rating": {
"truthiness": 0.3
},
"submitted_by": { "href": "agent/joef2016"},
"created": "2019-01-01T01:23:00.000Z"
}
Annotations
Another form of response to a claim is an annotation.
Amongst other things, this provides a method for responding to a claim, and having this information independently recorded and timestamped. This can allow agents to store their own data, and make their own interpretations of that data. (In this case the “FactBenchmark” service acts a little like a simple block chain - only without the block or the chain).
Arbitrary JSON can be posted in an annotation, for instance:
{
"ref": { "href": "claim/7dc0051f" },
"annotation": {"seq":1,"id":"fresh","changes":[{"rev":"1-967a00dff5e02add41819138abb3284d"}]},
"submitted_by": { "href": "agent/joef2016"},
"created": "2019-01-01T01:23:00.000Z"
}
Arbritary JSON will be stored (and, by default returned) as a content-hash, like this. If using the REST API it will be necessary to de-reference such content via the content resource. In such cases it may be preferable to use the GraphQL API which makes such de-refererencing easier.
{
"ref": { "href": "claim/7dc0051f" },
"annotations": [{ "hash": "a2f12df5" }],
"submitted_by": { "href": "agent/joef2016"},
"created": "2019-01-01T01:23:00.000Z"
}
Annotations can be placed under the following elements on each claim-response.
attribution(Generally but not always as support for check-worthiness)evidence(Truthiness, Supporting)not_supported(Truthiness, Not Supported)annotation(Arbitrary annotations)
For example to post an annotation indicating that a claim is not supported
{
"ref": { "href": "claim/7dc0051f" },
"not_supported": {"text": "Officials from the state of Hawaii certified that the copy of the certificate they provided to President Obama was authentic:",
"url": "http://healthuser.hawaii.gov/health/vital-records/News_Release_Birth_Certificate_042711.pdf"},
"submitted_by": { "href": "agent/joef2016"},
"created": "2019-01-01T01:23:00.000Z"
}
At this point the schema for annotations is completely open - so long as they are valid json. It is also possible to post content to the content end point first and then provide a reference to that in the annotation.
Based on data and feedback received from our members we may look to provide guidance as to preferred schemas for annotations, in the interest of improved information sharing between agents.
Benchmark and scoring
A benchmark consists of a set of check_worthy claims chosen by some objective criteria.
One format for benchmarks is to choose one check_worthy claim each hour and at each stage choose the claim with the highest, weighted importance not included in the benchmark already.
It is not necessary for a claim to be included in the benchmark for truth_rating responses to be received against it but obviously they don’t count towards the benchmark score until the claim is added to the benchmark.
Generally claims within a response will be accessed via a subscription so that realtime notifications can be received. However in REST format a benchmark with its list of claims may look like this.
{
"name": "December 2018 english twitter benchmark",
"description": "",
"claims": [
{
"timestamp": "2018-12-11T02:00:00.000Z",
"ref": { "href": "claim/1ab3f" }
},
{
"timestamp": "2018-12-12T03:00:00.000Z",
"ref": { "href": "claim/c283" }
},
{
"timestamp": "2018-12-13T04:00:00.000Z",
"ref": { "href": "claim/4b40" }
}
],
"submitted_by": { "href": "agent/factbenchmark"},
"created": "2018-12-10T01:23:00.000Z",
}
Points awarded and attributable to agents because of responses given to claims within that benchmark will also be made available under the benchmark object, in the GraphQL API.
Agent (Member)
For transparency, (almost) every piece of data in the API is attached to an agent record, including, wherever possible, data created by factbenchmark.org itself, acting as an agent.
{
"name": "joef2016",
"url": "https://xyz.com",
"affiliation": "XYZ Inc",
"description": "XYZ Agent 2016",
"profile_image_url":
"http://abs.twimg.com/sticky/default_profile_images/default_profile_normal.png",
"submitted_by": { "href": "agent/joef2016"},
"created": "2019-01-01T01:23:00.000Z",
"self": { "href": "agent/joef2016" },
}
Content (Content Cache)
In order to allow and sharing of associated data against claims an end point exists for posting arbitrary data. This data is retrieved by a content-hash of the concatenation of mime-type and data field (not including the submitted_by etc data). If two agents post the same data the content will only be stored once, using the first submission.
{
"hash": "a2f12df5",
"mime-type": "text/html",
"data": {"..."},
"submitted_by": { "href": "agent/joef2016"},
"created": "2019-01-01T01:23:00.000Z"
}
It is also possible to request that content be retrieved by the server, timestamped, cached and signed with the server key,
{
"hash": "a2f12df5",
"mime-type": "text/html",
"data": {"..."},
"source_url": "https://twitter.com/anindita-guha/status/1036924232595382273",
"timestamp-captured": "2019-01-01T01:02:00.000Z",
"signature": "d76a0ee281f84e08b04f73670122f4c9",
"submitted_by": { "href": "agent/joef2016"},
"created": "2019-01-01T01:23:00.000Z"
}
The mime-type hash-html should be treated in a special way. When retrieving content of this type any URLs of the form “hash:xxxx” can be de-referenced by recursive requests to this end-point to retrieve the associated content for that hash, along with the corresponding mime-type.
Cross cutting concerns
24Hr Time Delay
Claim-responses, like all data, eventually become available to all members of the benchmark. However, to ensure independence of submissions (no peeking at other people’s answers) claim-responses are not available to other agents, until after a 24hr time delay.
Submitted-by
For almost all resources there is a submitted_by entry automatically created on server with the user id of the authenticated user.
"submitted_by": { "href": "agent/joef2016"},
Created
For almost all resources there is also a created entry which is the server measured ISO-8601 UTC timestamp of the time on the server at the moment the entry was submitted.
"created": "2019-01-01T01:23:00.000Z"
Self ref
The server will allocate ids to objects on submission. REST responses (though not GraphQL responses) will include a self reference for each top level resource.
"self": { "href": { "item-type/6b051a34-e4b8-4c4f-83a2-de2c3c2f144e" } }
Idempotent, CRDT data model
Wherever possible the design of this API is designed to allow for idempotent (or at least CRDT, Conflict-Free Replicated Data) data update models. That means that records, once submitted, cannot be updated, only appended to.
The “hidden” log
As part of our guiding principles we aim to:
- have attributions for all data
- allow idempotent data schemas
- not delete any data
- follow a CRDT approach, generally.
To do this, while still allow graceful handling of errors we have a hidden log, with values like the following.
All end points, by default, hide data with a hidden log entry.
For now, hidden log entries will only be accepted by the user with the corresponding submitted_by reference or by a special FactBenchmark admin user.
As a safety valve, however, some facility for handling unexpected problems is provided by the ‘hidden’ log, with values like the following.
{
"ref": { "href": "claim/1ab3f" },
"reason": "accidental submission",
"submitted_by": { "href": "agent/joef2016"},
"created": "2019-01-01T01:23:00.000Z"
}
Hidden log entries will only be accepted by the user with the corresponding submitted_by reference or by the factbenchmark agent itself.
Special handling will be used to remove ‘hidden’ annotations and in other cases where it makes sense to do so. Generally speaking, however, once content is published to the API it is not revokable and cannot be removed.